
企業特化型AIは、どのStepで何を行っているのか
《要約》
現在、日本に登場している企業特化型AIサービスは、
学習済み Transformer モデルの推論能力を前提とし、その外側に業務特化型の設計・制御層と応用・運用層を構築することによって、実務上意味のある成果物を生成するシステムである、と位置付けられると思います。これは、先日(2026/04/15~17)のAI・人工知能コンフェレンスでの印象です。
そして、それら、企業特化型AIが行っている技術的 Step は、次のように整理できると思いました。
- Step 1 入力データの整理
- Step 2 プロンプト構築
- Step 3 参照情報の付与
- Step 4 推論実行
- Step 5 出力整形と検証
さらに、Transformer との関係を厳密に言えば、企業特化型AIは通常、Transformer の内部重みを直接更新していない、企業が主として制御しているのは、Transformer が計算対象として受け取る入力文脈と、その前後に置かれた業務処理の流れです。したがって、企業特化型AIの価値は、独自モデルの構築そのものよりも、推論をどのような文脈設計のもとで動かし、その結果をどのように点検し、業務に耐える成果物へ仕上げるかという設計力に宿っていると言えます。
この整理は、Transformer の内部構造を教育的に再現する理解とも、実社会におけるAIサービスの産業構造とも矛盾しません。むしろ、両者を一枚の図の上に置いて眺めるための、最も基本的な見取り図になるはずです。
そして、多くの事業会社にとって、また、IT・情報システム会社で、今はまだ取り組んでいないが、これからAIを使ったサービスに取り組んでいこうとする会社にとって、今後、どうしたらよいかの、技術的検討の一助になるに違いないと思っています。
はじめに
先日(2026年4月17日)のビックサイトでのAiI・人口工知能conference会場を駆け足で回ってきました。現在、我が国で多く提供されている産業・企業特化型のAIサービスの多くは、LLMをゼロから構築させているわけではないようです。ファインチューニングもしていないようです。(展示会社の営業マンからの聞き取りが主です。聞き間違い、見落としがあったらごめんなさい。)
つまり、すでに OpenAI、Anthropic、Google などによって大規模に学習された Transformer 系の学習済みモデルを利用し、その推論機能を外部から呼び出すかたちで実装されているものだった。
したがってこれらは、モデル内部の重みを作り替えることではなく、学習済みモデルの前後に置かれた制御と運用の仕組みを設計するところに拠っていると判断しました。この理解の上に立って、これらのシステムがどのような構造になっているのか、私なりに理解したところを以下記します。
私はAI(特にLLMを利用したサービス)構造を理解するために、まず概念を三つに分けたいと思います。
学習済みモデル
第一に、学習済みモデルとは、巨大なコーパスを用いた事前学習や、その後の微調整を通じて、すでに内部パラメータが形成された Transformer モデルを指します。
ここには、語彙ベクトル、Attention の重み、Feed Forward Network の係数、LayerNorm 関連の係数、出力射影行列などが含まれます。これらは学習の成果物であり、通常の企業利用者はこれを自ら形成しているわけではありません。
推論フェーズ
第二に、推論フェーズとは、学習済みモデルを固定したまま、入力文を受け取り、次のトークン候補の確率分布を計算し、その中から一つを選び、さらにその確定トークンを入力列に加えて次の計算へ進む反復過程を指します。このとき、学習時と似た演算は行われますが、誤差逆伝播もパラメータ更新も行われません。したがって、推論とは、学習済みの計算機構をそのまま使って応答を生成する段階です。
業務特化型の制御層と運用層
第三に、企業特化型AIサービスとは、こうした学習済みモデルの推論機能を利用しつつ、その外側に業務特化型の制御層と運用層を構築したシステムを指します。つまり、モデルの再教育を主眼とするのではなく、モデルに何を入力し、何を参照させ、どのような条件で出力させ、その結果をどのように点検・整形するかを設計することによって、業務上の価値を作り出す仕組みです。
この構造は、次のAIの3層構造として整理するのが最も分かりやすいと私は考えています。
Ⅰ AIの3層構造
(1)基盤構築層
基盤構築層とは、Transformer モデルそのものを設計し、大規模学習によって内部パラメータを形成する層です。ここでは、モデルのアーキテクチャ、語彙数、埋め込み次元、層数、Attention の構成、FFN の構成、Norm の位置、出力射影行列などが定められ、さらに学習を通じて各種重みが更新されます。OpenAI や Anthropic や Google などが担っているのは、基本的にこの層です。企業ユーザーは通常、この層の形成には関与しません。
(2)AI設計・制御層
AI設計・制御層とは、学習済みモデルの推論能力を、特定の業務に適した方向へ導くための制御を担う層です。ここで行われるのは、入力条件の整理、プロンプトの構築、模範文例や業務ルールの付与、生成条件の設定、出力結果の検証条件の設計などです。この層の中心的な役割は、Transformer の内部パラメータを変更することではなく、Transformer が計算する対象となる入力文脈を設計することにあります。現在の企業特化型AIサービスの競争力は、主としてこの層において現れるに違いありません。
(3)AI応用・運用層
AI応用・運用層とは、利用者が実際に触れるインターフェースと、業務上の入出力処理を担う層です。Excel や CSV の読込、フォーム入力、API 呼び出し、Word や PDF への出力、ログ保存、業務システムとの連携などがこれに含まれます。この層は、利用者にとって最も見えやすい層ですが、その背後では設計・制御層が入力文脈と出力点検の論理を支えています。私は、理解を早めてもらうためにUI層だとも言っています。

この三層構造を前提に、企業特化型AIサービスは、「基盤構築層を自前で作る」のではなく、既存の基盤構築層を利用し、その上に設計・制御層と応用・運用層を構築する事業である、と整理できます。
Ⅱ 企業特化型AIは、何をどのStepで行っているのか
以上の三層構造を、実際の技術的な流れに落として説明するために、私は企業特化型AIの実装を次のStep体系として定義しておきたいと思います。この Step は、業務用AIサービスが、学習済み Transformer を実際の業務処理の中でどのように用いているかを示すものです。
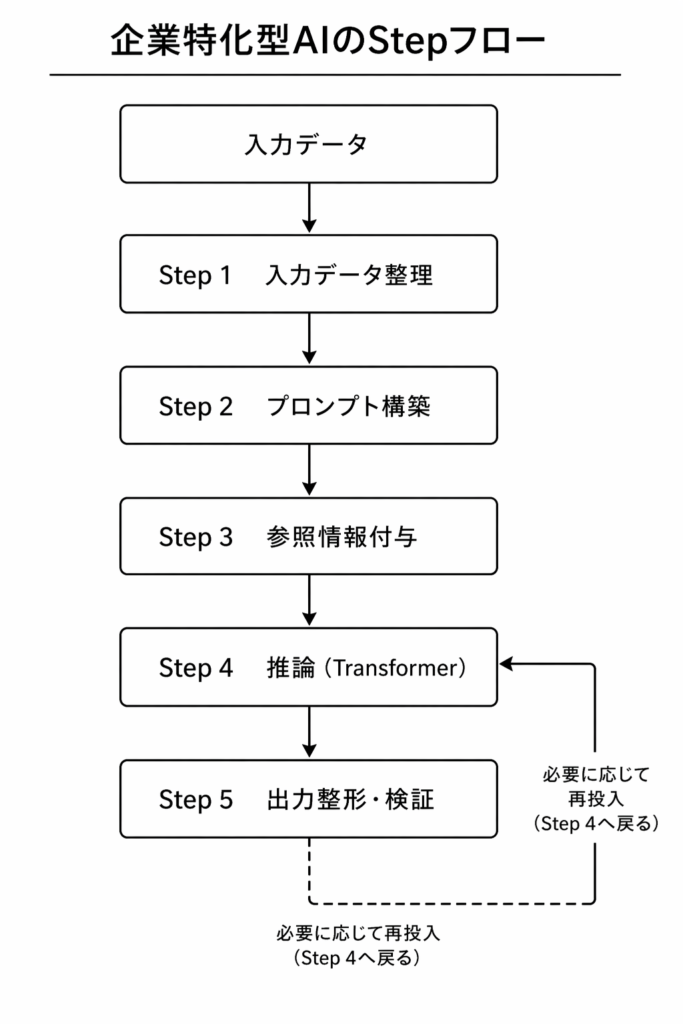
Step 1 入力データの整理
この Step では、実務で使われる Excel、CSV、データベース、フォーム入力などから必要な条件を読み取り、AIが扱える形式に整えます。たとえば、数値の型をそろえる、欠損値を確認する、単位を統一する、必要項目だけを抽出する、日付や住所の表記を整える、といった処理がここに含まれます。
この段階では、Transformer はまだ動いていません。したがって、ここは主として AI応用・運用層の処理ですが、後続のプロンプト設計に必要な素材を整えるという意味では、AI設計・制御層の準備段階でもあります。
Step 2 プロンプト構築
この Step では、学習済みモデルに与える指示文を構築します。たとえば、「あなたは○○です」「以下の条件に基づいて○○書を作成してください」といった役割指定や目的指定を行い、Step 1 で整理した条件を自然言語あるいは構造化テキストとしてまとめます。
ここで企業が行っているのは、Transformer の内部構造を変更することではありません。何を優先して読ませるか、どの業務文脈で応答させるかを、入力文脈の構成として決めているのです。したがって、この Step は AI設計・制御層の中核です。
Step 3 参照情報の付与
この Step では、模範文例、過去の事例、社内規程、定型表現、説明ルール、必要に応じて検索で取り出した関連情報などを、プロンプトの一部として付与します。
ここが特に誤解されやすい箇所です。模範文章を与えるからといって、その場でモデル内部の重みが更新されるわけではありません。LoRA や再学習を行っているのではなく、あくまで推論時点で参照可能な文脈材料を増やしているだけです。しかし、この「だけ」が軽い意味ではありません。
なぜなら、入力された指示文、条件文、模範文例は、すべてトークン列として Transformer 内部に入り、Self-Attention の計算対象になるからです。各トークンは他のトークンとの関連度を計算され、どの情報にどの程度注意を払うかが数値的に決まります。したがって、模範文章は、重み更新なしに、生成結果の文体や論理の運び方に大きな影響を及ぼします。ここでも、企業が制御しているのは Transformer の重みではなく、Transformer が計算する入力文脈の構成です。
Step 4 推論実行
この Step で初めて、学習済み Transformer モデルそのものが動作します。入力されたトークン列は埋め込みベクトルへ変換され、位置情報が加えられ、Q/K/V 計算、Self-Attention、Feed Forward Network、Norm、出力射影行列、Softmax を経て、次トークンの確率分布が計算されます。その分布から一つのトークンが選ばれ、そのトークンが入力列に付け加えられ、再び同じ過程が繰り返されます。講演資料では、この点が「次のトークンを探しに行き、選ばれたトークンを前の系列に付け足して文脈を更新する」という反復として示されています。
大事なのは、この Step では学習時と同様の演算機構が用いられているが、誤差逆伝播もパラメータ更新も行われないという点です。したがって、企業特化型AIサービスは、この Step において Transformer の内部層を「使って」はいますが、「調整して」はいません。
Step 5 出力整形と検証
この Step では、生成された出力を実務上使える成果物へと整えます。文書形式の整形、見出しや段落の調整、Word や PDF への出力、数値の整合性確認、社内基準との照合、ログ保存などがここに含まれます。たとえば、ある種の行政文書作成支援システムであれば、その文書を構成する章、節の、規定との一致をチェックし、文書全体を所定の書式へ整える処理がここに入ります。
この Step は、再び Transformer の外側の処理です。したがって、AI応用・運用層が大きな役割を担いますが、検証条件をどう設けるかという意味では、AI設計・制御層とも深く関係しています。ついでですが、実務では、この段階で整えられた文書を再度 Transformer に投入し、修正・補強・再整形を繰り返しながら最終成果物へ仕上げる設計が一般的だと思います。
Ⅲ 企業特化型AIは Transformer のどの部分を触っているのか
くどいようですが、「企業特化型AIは Transformer のどの層を触っているのか」という問いに、明確に答えておきたいと思います。結論から言えば、通常の企業特化型AIサービスは、Transformer の内部パラメータ層そのものには触っていません。すなわち、Embedding table、Wq・Wk・Wv、Feed Forward Network の係数、LayerNorm の係数、出力射影行列といった、学習済みモデル内部の重みを直接更新しているわけではありません。しかし同時に、「まったく関与していない」と言うのも不正確です。なぜなら、企業が Step 2 と Step 3 で構成したプロンプト、条件文、模範文例、業務ルールは、すべてトークン列として Transformer 内部へ入り、Self-Attention の計算対象となるからです。つまり、企業特化型AIは、Transformer の内部重みを変更するのではなく、内部重みが何を材料として計算するかを制御しているのです。
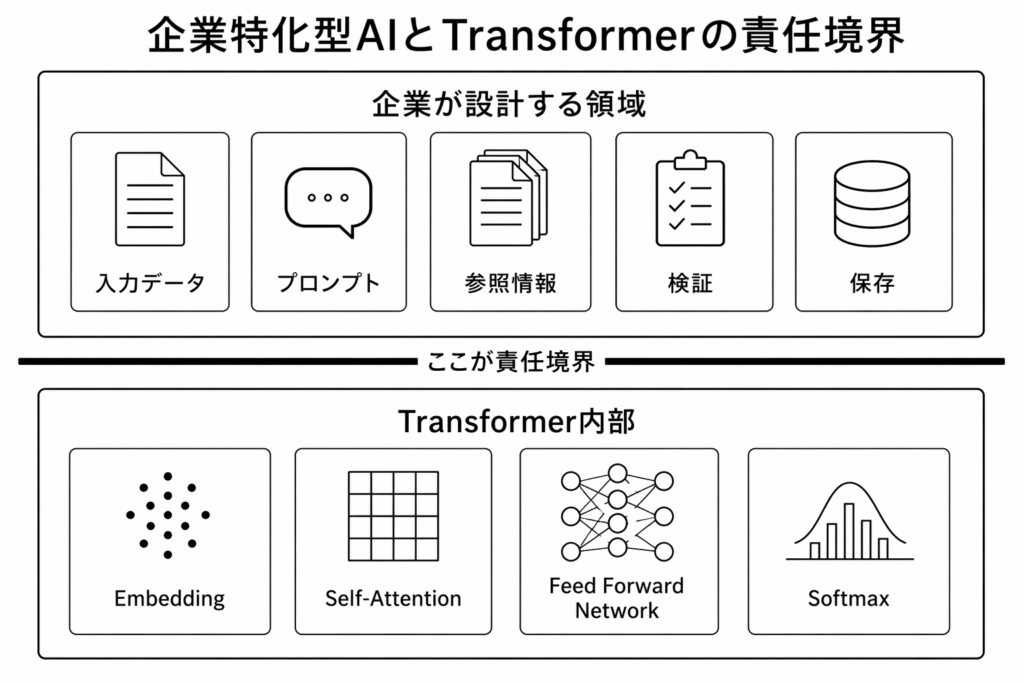
この意味で、より厳密に言えば、企業特化型AIが触っているのは、Transformer の「層そのもの」ではなく、Transformer の層に流し込まれる入力系列の構成です。そして、その入力系列が Self-Attention によって相互参照される以上、外側の設計は内部の計算結果に直接影響します。
したがって、企業特化型AIサービスが行っていることは、次のように定式化できます。
- 基盤構築層で形成された学習済み Transformer を利用する
- 設計・制御層で入力文脈と推論条件を構成する
- 応用・運用層で業務データを取り込み、生成結果を業務文書へ仕上げる
この三つが組み合わさって、はじめて実用的な企業特化型AIサービスになります。
Ⅳ 付論 AIの3層構造と AiAYN 図にもとづく位置づけ
ここで、以上の三層構造と Step 体系が、Transformer の内部動作とどのように対応しているかを、図示された学習フェーズの演算工程にもとづいて補足しておきます。

言語モデルの基本動作は、次のトークン予測として整理できます。入力列が与えられると、モデルは次に来る候補トークン全体について確率分布を計算し、そのうち一つが選択されると、その確定済みトークンを含んだ新しい入力列をもとに、再び次の確率分布を計算します。生成はこの反復として進み、温度や Top-p のような制御は、この各ステップの確率分布に対して適用されます。
学習フェーズでは、この次トークン予測が正解との比較を伴って実行されます。文章を一つずつ読み込み、次に来る語の確率分布を計算し、正解トークンとの差を損失として求め、その損失から逆伝播によってモデル内部のパラメータを少しずつ調整します。
ここで更新されるものとして、図に示されているように語彙ベクトル、Transformer 層の重み、出力側の投影行列が含まれます。一方で、層数、埋め込み次元、残差接続の有無といったアーキテクチャ自体は、設計者があらかじめ定めた枠組みであり、学習の成果物ではありません。
この整理を、私の Transformer 再現プロジェクトの Step 体系で言い換えると、文末の図のようになります。
F 系列は、Transformer が内部で何を計算しているかを分解して示す軸です。
具体的にはトークン化、埋め込み、位置情報付与、Q / K / V 計算、Self-Attention、Feed Forward、投影、出力という一連の演算がここに含まれます。T 系列は、それらが損失計算と逆伝播を通じてどのように更新されるかを示す軸です。そして I 系列は、学習が終了したあと、その同じ計算機構を、パラメータ更新なしに反復的なテキスト生成として動作させる軸です。
ここから明確になることがあります。
F / T / I という Step 体系は、基盤構築層の内部動作を理解するための分析軸です。
一方で、実社会の企業特化型AIサービスは、この第一層を自ら形成しているのではありません。すでに形成された基盤構築層を前提として、設計・制御層、応用・運用層をその外側に構築しています。したがって、教育的 Step 体系と産業構造としての三層モデルは、対立する概念ではありません。それらは内部構造を見る尺度、外部構造を見る尺度という、異なる方向から同じ対象を観察しているものです。
推論フェーズでは、学習済みモデルが、辞書、Transformer 層の重み、モデル構造を参照しながら、入力トークン列の関係性を数値的に処理し、Softmax によって最も確率の高い次トークンを選択し、それを再び入力列へ加えながら応答テキストを生成していきます。
繰り返しますが、重要なのは推論の演算そのものはモデル内部で実行されるが、何を入力し、何を参照させ、どの条件で呼び出し、どう利用可能な成果物へ整形するかは、モデル外部で設計されているという点です。
内部重みを直接更新から、しているわけではないため、基盤構築層の内部構造を作り替えているわけではありませんが、。しかし、プロンプト、条件文、模範文例、履歴文脈を入力系列として構成することによって、Self-Attention が参照する情報の配置を決定しています。したがって、企業特化型AIはTransformer の内部層を変更しているのではなく、内部層が計算する対象となる文脈を設計しているのです。
なお、本稿の記述は、理論的整理や文献解説にとどまるものではなく、実装されたコードと、その動作の観察結果に基づいています。参照元となる Transformer 再現実装プロジェクトは、次のリポジトリに公開してあります。
https://github.com/koichikamachi/attention-transformer-reproduction
GitHub Repository attention-transformer-reproduction(Public) Author: Koichi Kamachi, CPA Framework: TensorFlow 2.x / Google Colab License: MIT
Transformer 再現プロジェクトの Step 体系
| F0 | 環境セットアップ | Python、TensorFlow 2.x、SentencePiece などの実行環境を Google Colab 上に整える段階。ライブラリの読み込みと動作確認までを行い、以後の処理が走る土台をつくる。 |
| F1 | コーパス作成 | 学習と動作確認に用いるテキストデータを準備する段階。対象となる文章群を収集・整形し、UTF-8 の素のテキスト列として保存する。ここで用意したコーパスは、次段のトークナイザー訓練と、後続の学習データ化の両方に供される。 |
| F2 | トークナイザー訓練(SentencePiece) | F1 で用意したコーパスを入力として、SentencePiece によりサブワード単位の語彙表を学習させる段階。結果として、「テキストをどのような単位に分割し、どの ID を割り当てるか」を定めた辞書(.model / .vocab)が生成される。 |
| F3 | トークナイザー読み込みと encode() テスト | F2 で生成したトークナイザーを読み込み、任意のテキストを実際にトークン ID 列へ変換(encode)し、また ID 列からテキストへ戻せる(decode)ことを確認する段階。以後の F4 以降が受け取る「入力 ID 列」という形式が、ここで初めて現れる。 |
| F4 | Embedding 層の実装 | F3 で得られるトークン ID 列を、固定次元の密ベクトル列へ変換する層を実装する段階。ID という離散記号が、モデルが扱える連続値の表現に置き換わる。ここで作られる Embedding table は、学習によって更新される重みの一つである。 |
| F5 | Positional Encoding の実装 Embedding | ベクトルそのものには語順情報が含まれないため、各位置に対応する位置情報ベクトルを加算する段階。これにより、同じ語でも文中の位置に応じて異なる表現を持つようになり、Self-Attention が順序を扱えるようになる。 |
| F6 | Self-Attention(Q / K / V 行列生成と注意重み計算) | F5 の出力から、重み行列 Wq, Wk, Wv を通じて Query・Key・Value の三つの行列を生成し、QK の内積とスケーリング、Softmax によって注意重みを計算し、その重みで V を加重和する段階。Transformer の中核的な処理である「どのトークンがどのトークンをどの程度参照するか」がここで決まる。 |
| F7 | Feed-Forward Network と残差接続・LayerNorm | Self-Attention の出力に対して、各位置ごとに独立に働く二層の全結合ネットワーク(FFN)を通し、さらに残差接続(入力を出力に加える)と LayerNorm(分布の正規化)を適用する段階。Transformer ブロック一層分の処理は、F6 と F7 の組み合わせで完結する。 |
| F8 | 語彙空間への射影と Softmax 出力 | 最終層の出力ベクトルに、出力側の射影行列を掛けることで、語彙数と同じ長さのスコアベクトル(logits)を得る段階。これに Softmax を適用すると、語彙全体にわたる次トークンの確率分布が得られる。生成時には、この分布から一つのトークンが選ばれる。 |
| T1 | Transformer モデル構築 | F4〜F8 で実装した各機能ブロックを、一つの tf.keras.Model(あるいは同等のクラス)として組み上げる段階。ここで初めて、入力 ID 列を受け取り、次トークンの確率分布を出力する一個のモデルが成立する。 |
| T2 | Optimizer と Loss 関数の設定 | 学習に用いる最適化手法(Adam など)と損失関数(次トークン予測における交差エントロピー)を設定する段階。モデル内部の重みを、どの基準で、どの方向に、どの大きさで更新するかが、ここで決まる。 |
| T3 | 学習ループ実行(Epoch) | コーパスを入力として、「予測 → 損失計算 → 逆伝播 → 重み更新」という一連の処理を反復する段階。エポックを重ねるごとに損失が減少し、Embedding table、Attention 各行列、FFN 係数、LayerNorm 係数、出力射影行列といった重みが少しずつ整えられていく。 |
| T4 | 学習済みモデル保存 | T3 によって更新された重みを、checkpoint ファイルまたは SavedModel として保存する段階。ここで初めて、「学習済みモデル」がファイルとして外部に取り出せる形で存在するようになる。 |
| T5 | 推論(Inference) | フェイズ T4 で保存した学習済みモデルを読み込み、重みを固定したまま入力トークン列に対して次トークンの確率分布を計算し、一つのトークンを選び、それを入力列に付け足し、再び同じ処理を繰り返すことで、テキストを生成する段階。学習時と同じ計算機構を用いるが、逆伝播も重み更新も行われない点が T3 との決定的な違いである。 |
第1層 AI Model Foundation Layer(AI基盤構築層) この層には、Embedding、Positional Encoding、Self-Attention、Feed-Forward Network、Projection、Softmax が含まれる。Step 体系でいえば、F4〜F8 および T1〜T3 がこの層を構成する。Q・K・V 行列の生成、注意重みの計算、文脈表現の形成はここで行われる。モデルそのものであるこの層は、企業側が書き換えられる領域ではない。
第2層 AI Design & OptimizationControl Layer(AI設計・最適化制御層) この層には、プロンプト設計、検索(RAG)、文書選択、温度設定、推論制御が含まれる。Transformer の内部構造は変更されないが、どの文書を、どの順序で、どの形式でモデルに渡すか、すなわち入力条件がここで決定される。Embedding、Attention、Softmax の処理自体は変更されないが、それらの処理に入るデータは、この層で決定される。
第3層 AI Application & Operations Layer(AI応用・運用層) この層では、入力画面、CSV、Word 出力、監査ログ、アクセス制御が扱われる。Transformer の内部計算からは切り離されており、ユーザー入力、システム出力、記録保存という業務処理がここで行われる。
以上の三層区分は、Transformer を実装し、動かし、保存し、推論させる過程において、変更可能性と責任の境界として観察された区分に対応する。